SIMD Libraries in C++ - Jeff Garland - CppNow 2023

Vložit
- čas přidán 31. 07. 2023
- www.cppnow.org
/ cppnow
---
SIMD Libraries in C++ - Jeff Garland - CppNow 2023
Slides: github.com/boostcon
---
Vector processing to accelerate computation developed more than forty years in the 1970's. At the time limited to extremely expensive machines dedicated to large mathematical problems. By 2016, single instruction multiple data (SIMD) registers and pipelines started occupying the silicon of processors available on every desktop. While the early promise of SIMD seemed to rely on the idea of the compiler vectorizing loops automatically, that mostly has not happened. Instead, over time programmers started exploring how to directly utilize SIMD by altering algorithms to directly exploit parallelism. The performance results were staggering with some SIMD algorithms producing trouncing the performance of highly optimized code. In 2023, a new era is dawning where portable SIMD applications can be built on top of libraries targeted at application developers. Most notably for c++ std::simd.
The goal of the session is to provide a starting point for developers interested in exploiting SIMD in c++. This session will be a tour through various c++ libraries utilizing SIMD. We will overview application level libraries for json parsing, compression, and crc processing that keep all the SIMD details below the interface. As well as 'developer libraries' that provide abstractions to enable the development of new parallel algorithms. We'll discuss the design choices and trade-offs made by these libraries.
The final part of the talk is an introduction to the proposed for c++26 std::simd and all of it's components. This includes data-parallel types via std::simd and it's related traits and Abi facilities. In addition to types the talk will cover algorithms and the role of std::simd_mask. We will also cover the nuts and bolts of getting access to the preliminary implementation via gcc11 and up. This session will be an adjunct to Library in a Week where we will be working on writing parallel algorithms using std::simd.
wg21.link/P1928
---
Jeff Garland
Jeff Garland has worked on many large-scale, distributed software projects over the past 30+ years. The systems span many different domains including telephone switching, industrial process control, satellite ground control, ip-based communications, and financial systems. He has written C++ networked code for several large systems including the development high performance network servers and data distribution frameworks.Mr. Garland’s interest in Boost started in 2000 as a user. Since then he has developed Boost.date_time, become a moderator, served as a review manager for several libraries (including asio and serialization), administered the Boost wiki, and served as a mentor for Google Summer of Code. Mr. Garland holds a Master’s degree in Computer Science from Arizona State University and a Bachelor of Science in Systems Engineering from the University of Arizona. He is co-author of Large Scale Software Architecture: A Practical Guide Using UML. He is currently Principal Consultant for his own company: CrystalClear Software, Inc.
---
Video Sponsors: think-cell and Bloomberg Engineering
Audience Audio Sponsors: Innoplex and Maryland Research Institute
---
Videos Filmed & Edited By Bash Films: bashfilms.com/
CZcams Channel Managed & Optimized By Digital Medium Ltd: events.digital-medium.co.uk
---
CppNow 2024
www.cppnow.org
/ cppnow
---
#boost #cpp #cppprogramming - Věda a technologie








Good talk :)
As for EVE code:
- wide v{4} is the value set in the wide register
- the second parameter is the cardinal of the wide in case you want to so stuff like size - i or something. This needs to be made clearer.
- wide size is fixed and is usually assert. There is no dynamic sized wide.
:) Thanks for the shout out.
Now this gets me excited. Glad to see SIMD is getting some love in cpp 26. I probably won't see that at work for a couple of years after release but I'm still excited. I can only imagine how wonderful it'd be to have a native portable SIMD solution
1:17:50
I strongly prefer `==` returning a mask for data parallel types, not a bool. This is necessary for generic code.
For code that is generic between scalar and SIMD-vector to work, each lane of the vector has to execute the same way as the scalar (but e.g. using masks instead of branches).
This is what comparison operators returning masks enables.
Returning bools suddenly changes the meaning of the code when you go from scalar to vector: the result of one lane suddenly depending on the neighboring lanes, violating the basic tenant of data parallelism: data should effectively execute independently in parallel.
Only people who haven't really done any SIMD programming think returning `bool` is a good idea.
Appreciate you trying eve! I'm sorry it wasn't very intuitive.
You can find my and Joel's talk:
SIMD in C++20: EVE of a new Era
I also think that my "My First Simd" talk is a good place to get a first overview of how to do cool things with simd.
I show strlen, find, reduce, insclusive_scan and remove.
Regardless of confusions:
Size of the register is known at compile time. wide will select the default one for the architecture in question.
You can override it: wide
Note: there is a big problem of what's "default size" on avx512, we are working on detecting compiler flags but not done yet.
The second parameter in the lambda is size. Otherwise getting it is very clumsy. [](int i, int size) { return size - i - 1; } will generate you values in reverse order.
wide(float*) is same as load(const float*). This is maybe too cute.
I've started learning C++ beginning in mid October, but I have been playing Eve Online off and on since 2004. MATLAB for mechanical engineering was my only experience with a pseudo programming language.
Stumbling upon this presentation was ultra informative.
The key to getting good auto factorization - use a static size (preferably cache line aligned) frame to iterate unknown size data , finish off any remaining items at the end in a separate loop, this way most of the ops are vectorized and only the unpadded remained is done in scalar.
"Don't operator overload that isn't the same as everywhere else" ranges already do it with the | operator. But yes in general that is a very valid point
You know... it's a good talk, you know
What surprises me a lot is even with the existence of such amazing libraries, which people have used, and has features, the standard proposal cuts these down and also seems to produce worse assembly. If that's the case, why not focus on divert effort to language features instead? I definitely am ignorant of the constraints, so please do educate me! Reflection is still up in the air, and the slow evolution is pushing me to use other languages. I definitely am ignorant of the constraints, so please do educate me, and I do not mean that in a sarcastic way.
Great talk! Nice to see simd native support. Hopefully the problems are ironed out and it makes it for C++26!
One reason I've heard is people in highly constrained or regulated industries can't easily bring in third party libraries so having a basic version of useful things in the standard library helps them a lot.
Regarding the operator==, I believe it should return the mask to keep SIMD mentality, but maybe the mask could provide an operator bool that implicitly uses all_of. Code that includes branches like if(a==b) is clearly not expecting SIMD, and will take the usual meaning, while branchless code will never ask for boolean conversion.
I really hope this gets added, finally a reason to upgrade c++ to a new version
c++ is supposed to be fast, with this it will make it run 8 to 16 times faster.
currently the main issue with simd is platform dependency, so if the standard is able to provide us with this and be able to automatically switch intrinsic instructions based on the platform without us worrying that would be a really big favor to everyone.
Also i disagree with this guy at 1:17:25 complaining about the == mask, anyone who has programmed with shaders would already know that every operator or instruction you do will be applied to every element, thats why its called single instruction multiple data, it also helps us make the code more seamless, organized and more similar to shading languages.
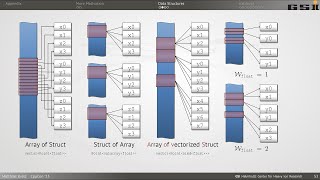
I quite like the ascii art actually.
The SIMD instructions should be added into C standard, rather than the CPP standard, because some systems, eg. trueNAS scale, using sse4.2/AVX to evaluate ZFS performance at booting time, or just simply keep inline assembly language capability in both C/CPP compilers... anyway this feature comes too late..
“Simply keeping inline assembly in compilers” is already done by include immintrin.h for decades