its really a great video for someone to understand the high-level architecture of modern data stack. It would be great if you can start a in-depth data modelling playlist as it plays a crucial role in designing data engineering pipelines. Thank you
Really appreciated seeing the different examples, as it helped to underline how the stages remain the same, regardless of the specific tools being used.
Great content! I had a question - why would companies choose to use standalone ELT / ETL providers (e.g. Stitch, Matillion) over the native Amazon Glue / Azure data factory? Wouldn’t it be easier to use the cloud provides as it would be more integrated?
How did I not found your channel much earlier. Your videos are extremely concise, well visualized and informative. I am a Data Scientist transitioning to Data Engineering (because in Gaming I am also always the healer/support 😉)
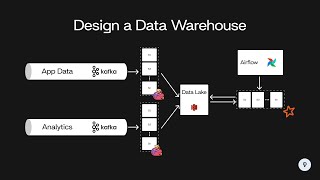
I think it would be really cool to see how, once the data is landed in the data lake, you bring all the data together, since you wont necessarily have matching IDs from different sources to work with.
Hello! Where does ETL tools like Informatica or Alteryx land in a modern data architecture? Or not at all because we have dbt / azure data factory/ SQL script ?
Heh the concept you presented (collect data from various sources into Snowflake DWH) & transform it via dbt is exactly what we do for customer :) I worked in on-premise where we handled everything via scripts & Jenkins & must say this modern approach is in many aspects better :)
What if I want to add local data Marts to that traditional flow ? Would that be a bad idea? I just want to set up local data Marts and connect them to a data lake (and somehow make it replace the data warehouse. And if that's not possible, connect them to the warehouse). Can you please make a video to show us the disadvantages of this set up? Thank you in advance
I was curious coming from your "simple, small/mid-sided" data email. I expected something on efficient analytics databases like duckdb/motherduck/hydra/firebolt? Do you plan to cover that in a future episode? Basically the other parts of the stack would stay the same just the processing goes from snowflake/synapse/bigquery to one of these more efficient, lower-cost tools.
Thanks for reading the email and checking out this video! I actually have not used any of those tools in depth so I can't speak much on them at this time. But perhaps in the future!
Is it meant to only add the new data to the datalake or the full copy? As an example we are using odoo as our erp system. the sql database has a unpacked size of 6gb. if i would copy it daily the amount of data would get huge. on the one hand every data would be persistend with it and i could have more options to analiye but is this really best practice?
What is the use case for brining in all of the data into the data lake prior to the data warehouse? Is it possible that you bring some data into your data warehouse from the source systems directly and some data in from s3 buckets?
Keeping it in a data lake: - Gives a historical log of all source data in it's raw form (before any DW transformations) - Allows you to load data faster, and separately from the DW transformation processes - Provides a clear location for all source data to be landed, whereas a DW might have other processes involved Plus storage is less expensive nowadays so it's less of a problem to storing it all this way (to an extent). I'm probably missing other things but that's just off the top of my head. Plus storage is less expensive nowadays so it's less of a problem to storing it all this way (to an extent). Hope that helps!
@@KahanDataSolutions Interesting, thanks for the reply! I guess my only follow up we be around your first point about keeping a historical log. Couldnt this be done just as easily in the data warehouse, assuming you are dealing with structured data? The data could be dumped into the DW just as raw as it could be in the data lake right?
What are some examples of the difference between the data warehouse and data models? So like if you build a star schema data warehouse, couldn't tableau just connect directly to that rather than another layer of models? Or are you building the models to differentiate the data used by different groups (i.e. a marketing mart)? Also would you typically materialize those as OBT views or physical tables? Kind of can't wrap my head around that part. Thanks!
Great question, and the short answer is both approaches you're mentioning are possible. It's typically a matter of how much logic you want to hold in the database/queries vs offloaded to Tableau or reporting tool. I find that a lot of companies start with going from Data Warehouse right to reporting tool, but then end up shifting to having a handful of custom data mart models in between that get tied to different reports. Ideally, you can then reuse the same mart for multiple reports. The reason teams often struggle when adding a lot of logic directly in reporting tools is that as you add more and more complex logic it becomes really hard to track & troubleshoot. It basically gets lost within reports. It's easier in the short term but results in duplication, conflicting logic and more. You also don't have easy version control, testing, transparency, etc. like you would have if you wrote it in sql (and with a tool like dbt) and deployed it to a DB first. If you don't want to add an extra mart layer, it's also possible to handle a lot of that complexity still within the warehouse layer. It's really up to your team and how you want to organize it. For the second part of your question on materialization, again there's no one-size fits all answer. But I find that the marts layer is typically more of a OBT (table) approach, or closer to it. For example, you can tie together a bunch of DW tables to create a common "summary" view or on the granularity of something that can be re-used for multiple reports. But as you said, it's also acceptable to simply create additional custom models simply to separate user groups. I've seen all of the above done and it is often a case by case basis. This was a LONG winded response, but hopefully was helpful. Data strategy can be confusing but at the end of the day is just finding a way to organize tables/views/data in ways that work best for you.
@@KahanDataSolutions Thanks for spending the time to write that up, that was very helpful. I had not really thought of version control over the mart logic since our current BI tool sort of handles that, so that makes a lot of sense. I guess I got confused since we do all the things you mentioned within what we call the "data warehouse" layer in our architecture and wouldn't call that out separately on a diagram probably, so I was assuming there was something magical happening there that I couldn't figure out after having see that architecture a few times. Makes sense to call it out I guess I just wasn't bright enough to figure out why. Appreciate your content.
@@gatorpika This is really an amazing question, I am in a situation where management want near real-time dashboards. My manager wants to plug Tableau directly to the DB(it's AWS dynamodb) using ODBC driver. But my thinking is, stream the data from DynamoDB with dynamo streams/kinesis firehose use AWS glue to crawl and maybe change datatypes then load it to redshift or s3 where I can connect with Tableau. I much appreciate your views, thanks.
@@kinuthiasteve4505 I'm not a streaming expert but yeah I think you are on the right track. I have not used Tableau in years, but it used to be more of an analysis platform for historical data, not a streaming platform, right? Like you have to manually refresh the data? We are working on something like that now where we use Kafka to consume the source data and that feeds some apps that display the real time stream and also feeds our data platform where history is accumulated and accessible via a BI tool like Tableau.
Amazing video man. As a senior CS student and aspiring data engineer, I get none of this in school! Love the channel man. Are you on instagram / twitter?









►► The Starter Guide for Modern Data (Free PDF) → www.kahandatasolutions.com/startermds
its really a great video for someone to understand the high-level architecture of modern data stack. It would be great if you can start a in-depth data modelling playlist as it plays a crucial role in designing data engineering pipelines. Thank you
Really appreciated seeing the different examples, as it helped to underline how the stages remain the same, regardless of the specific tools being used.
Just discovered your channel recently and I wanted to say it is a gold mine! Keep making this kind of content!
Appreciate it! Glad to have you here
Great video! Your pace, presentation and visuals are really on point.
Keep up the good work :)
I just discovered your videos. They are excellent. Clear, concise and to the point. Great content! Thanks so much!
Glad you like them!
awesome this is really useful. Keep making these sample architecture videos.
Great content! I had a question - why would companies choose to use standalone ELT / ETL providers (e.g. Stitch, Matillion) over the native Amazon Glue / Azure data factory? Wouldn’t it be easier to use the cloud provides as it would be more integrated?
How did I not found your channel much earlier. Your videos are extremely concise, well visualized and informative. I am a Data Scientist transitioning to Data Engineering (because in Gaming I am also always the healer/support 😉)
Love that - welcome to the channel!
I think it would be really cool to see how, once the data is landed in the data lake, you bring all the data together, since you wont necessarily have matching IDs from different sources to work with.
Best data modeling videos I've come across so far, great job!
Simple and to the point explanation. I think it very important to understand the concepts as well not just tools, very useful for interviews also.
Glad it was helpful!
These design and architecture videos are great to learn the concepts in bite sizes. Looking forward to more such videos.
Glad you liked it!
Hello! Where does ETL tools like Informatica or Alteryx land in a modern data architecture? Or not at all because we have dbt / azure data factory/ SQL script ?
Heh the concept you presented (collect data from various sources into Snowflake DWH) & transform it via dbt is exactly what we do for customer :) I worked in on-premise where we handled everything via scripts & Jenkins & must say this modern approach is in many aspects better :)
Snowflake + dbt is my favorite stack as well. Doesn't have to be overly complex to be effective.
What if I want to add local data Marts to that traditional flow ? Would that be a bad idea?
I just want to set up local data Marts and connect them to a data lake (and somehow make it replace the data warehouse. And if that's not possible, connect them to the warehouse).
Can you please make a video to show us the disadvantages of this set up? Thank you in advance
Wow, great content broken down simply.... Thank you.
awesome explanation and visuals! Keep it up!
Can I ask where do you put the HDFS in the current data architec stack?
I was curious coming from your "simple, small/mid-sided" data email. I expected something on efficient analytics databases like duckdb/motherduck/hydra/firebolt? Do you plan to cover that in a future episode? Basically the other parts of the stack would stay the same just the processing goes from snowflake/synapse/bigquery to one of these more efficient, lower-cost tools.
Thanks for reading the email and checking out this video! I actually have not used any of those tools in depth so I can't speak much on them at this time. But perhaps in the future!
Great content, simple and clear.
Much appreciated!
Is it meant to only add the new data to the datalake or the full copy? As an example we are using odoo as our erp system. the sql database has a unpacked size of 6gb. if i would copy it daily the amount of data would get huge. on the one hand every data would be persistend with it and i could have more options to analiye but is this really best practice?
What is the use case for brining in all of the data into the data lake prior to the data warehouse? Is it possible that you bring some data into your data warehouse from the source systems directly and some data in from s3 buckets?
Keeping it in a data lake:
- Gives a historical log of all source data in it's raw form (before any DW transformations)
- Allows you to load data faster, and separately from the DW transformation processes
- Provides a clear location for all source data to be landed, whereas a DW might have other processes involved
Plus storage is less expensive nowadays so it's less of a problem to storing it all this way (to an extent).
I'm probably missing other things but that's just off the top of my head. Plus storage is less expensive nowadays so it's less of a problem to storing it all this way (to an extent).
Hope that helps!
@@KahanDataSolutions Interesting, thanks for the reply! I guess my only follow up we be around your first point about keeping a historical log. Couldnt this be done just as easily in the data warehouse, assuming you are dealing with structured data? The data could be dumped into the DW just as raw as it could be in the data lake right?
Superb
Really useful ❤
Glad it was helpful!
What are some examples of the difference between the data warehouse and data models? So like if you build a star schema data warehouse, couldn't tableau just connect directly to that rather than another layer of models? Or are you building the models to differentiate the data used by different groups (i.e. a marketing mart)? Also would you typically materialize those as OBT views or physical tables? Kind of can't wrap my head around that part. Thanks!
Great question, and the short answer is both approaches you're mentioning are possible.
It's typically a matter of how much logic you want to hold in the database/queries vs offloaded to Tableau or reporting tool.
I find that a lot of companies start with going from Data Warehouse right to reporting tool, but then end up shifting to having a handful of custom data mart models in between that get tied to different reports. Ideally, you can then reuse the same mart for multiple reports.
The reason teams often struggle when adding a lot of logic directly in reporting tools is that as you add more and more complex logic it becomes really hard to track & troubleshoot. It basically gets lost within reports. It's easier in the short term but results in duplication, conflicting logic and more.
You also don't have easy version control, testing, transparency, etc. like you would have if you wrote it in sql (and with a tool like dbt) and deployed it to a DB first.
If you don't want to add an extra mart layer, it's also possible to handle a lot of that complexity still within the warehouse layer. It's really up to your team and how you want to organize it.
For the second part of your question on materialization, again there's no one-size fits all answer. But I find that the marts layer is typically more of a OBT (table) approach, or closer to it.
For example, you can tie together a bunch of DW tables to create a common "summary" view or on the granularity of something that can be re-used for multiple reports. But as you said, it's also acceptable to simply create additional custom models simply to separate user groups. I've seen all of the above done and it is often a case by case basis.
This was a LONG winded response, but hopefully was helpful. Data strategy can be confusing but at the end of the day is just finding a way to organize tables/views/data in ways that work best for you.
@@KahanDataSolutions Thanks for spending the time to write that up, that was very helpful. I had not really thought of version control over the mart logic since our current BI tool sort of handles that, so that makes a lot of sense. I guess I got confused since we do all the things you mentioned within what we call the "data warehouse" layer in our architecture and wouldn't call that out separately on a diagram probably, so I was assuming there was something magical happening there that I couldn't figure out after having see that architecture a few times. Makes sense to call it out I guess I just wasn't bright enough to figure out why. Appreciate your content.
@@gatorpika This is really an amazing question, I am in a situation where management want near real-time dashboards. My manager wants to plug Tableau directly to the DB(it's AWS dynamodb) using ODBC driver. But my thinking is, stream the data from DynamoDB with dynamo streams/kinesis firehose use AWS glue to crawl and maybe change datatypes then load it to redshift or s3 where I can connect with Tableau. I much appreciate your views, thanks.
@@kinuthiasteve4505 I'm not a streaming expert but yeah I think you are on the right track. I have not used Tableau in years, but it used to be more of an analysis platform for historical data, not a streaming platform, right? Like you have to manually refresh the data? We are working on something like that now where we use Kafka to consume the source data and that feeds some apps that display the real time stream and also feeds our data platform where history is accumulated and accessible via a BI tool like Tableau.
Amazing video man. As a senior CS student and aspiring data engineer, I get none of this in school! Love the channel man. Are you on instagram / twitter?