Class Weights for Handling Imbalanced Datasets

Vložit
- čas přidán 6. 05. 2019
- In scikit-learn, a lot of classifiers comes with a built-in method of handling imbalanced classes. If we have highly imbalanced classes and have no addressed it during preprocessing, we have the option of using the class_weight parameter to weight the classes to make certain we have a balanced mix of each class. Specifically, the balanced argument will automatically weigh classes inversely proportional to their frequency.
This video demonstrates the power class_weight='balanced'
Link to the notebook - github.com/bhattbhavesh91/imb...
If you do have any questions with what we covered in this video then feel free to ask in the comment section below & I'll do my best to answer those.
If you enjoy these tutorials & would like to support them then the easiest way is to simply like the video & give it a thumbs up & also it's a huge help to share these videos with anyone who you think would find them useful.
Be sure to subscribe for future videos & thank you all for watching.
You can find me on:
GitHub - github.com/bhattbhavesh91
Medium - / bhattbhavesh91
#ClassImbalance #ClassWeight #machinelearning #python #deeplearning #datascience #youtube



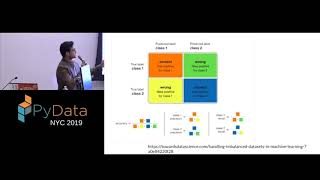





Something went wrong while using pd.crosstab! So the updated confusion matrices are as follows -
At 2:06
The correct confusion matrix is
93800 78
38 71
At 5:19
The correct confusion matrix is
91548 13
2290 136
At 8:30
The correct confusion matrix is
93791 30
47 119
Sorry for the mistake :)
Dont you have the previous video you referred to?
Hi, Thanks for the amazing video. I have 2 questions:
First question is similar to other posts. Why the weights are chosen to be 'x' and '1-x'?
Second is about the working of GridSearchCV. I think the it searches across the 20 intervals from 0.05 to 0.95. Then, how the optimum value of x for 0 was found to be 0.097 and not 0.1? (And similarly 0.902 for 1 and not 0.9?)
yes you should have used sklearn confusion matrix method
Hello , could you tell me why I have ValueError: Invalid parameter ratio for estimator SMOTE(). Check the list of available parameters with `estimator.get_params().keys()`. for row 51
This was helpful. Thanks
Thank you so much
Glad it helped!
nice explanations
Very insightful! I will try this soon and come back with feedback! :) Have a nice day and thank you for your efforts!
Thank you soo much this is really interesting and it was really helpful for my project
Glad it was helpful!
@@bhattbhavesh91 come on replying only for girls ha ha...!
@@bhattbhavesh91 hello prof.
With the f_score of 77% , is it okay to deploy this particular model into production?
very helpful thankyou
You're welcome!
Amazing sir👌👌
Thanks a lot 😊
hi, when you use cv for optimal weight, why does the weight need to be "x" and "1-x" ? The "balanced" option produces weights that do not sum up to become 1. so why do we use gridsearch to find weights in the range [0,1] ?
True Positive is 0, it means model incorrectly classifies all the frauds (class=1), but we want to more focus on true positive as in case of credit fraud detection. Why this is happening
Thanks, nice video..
What do you recomend more...down sampling or using class_weights ?
hi, could you explain How to use class weight when we have multiclass? Like.. how do we get to know best parameters of classs_weight after hyperparameter tuning??
I have checked your videos regarding handling imbalanced datasets. Just wanted to know, what is the recommended technique to use for such cases -
1. If use undersampling then there's a potential chance of losing huge data
2. If I use class_weights, it gives me a reasonable f1
3. If I use SMOTE, it also gives me a good performance. But I believe there might lie a probability that the synthetic data points might look like the test cases, which is indirect data leakage
What do you recommend and why?
Hi Bhavesh, how can we do grid search for multi-class. As you have set 2 class weights to x and 1-x. How to set it for 4 classes.
Yeah, that's I was also wondering
Niceeeeeeeeee
Hi, thanks for teaching. I have a question. How can we use class weight for bayesian network?
hi, why to use ROC curve ?? precision recall has to be used for imbalanced data set isn't it ???
What if we have a multilabel or even multioutput task? In my experience class_weights don t work in those cases. Pls correct me if I am wrong
Hi, Thanks for the detailed explanation, i am not able to access your notebook
How to use class weight when we have multiclass? Like.. how do we get know best parameters of classs_weight after hyperparameter tunining??
Plz answer if u got it??
Sir, Can we use 'class_weight = balanced' for multiclass classification and deep learning also??
Bro did you get to know, how to perform it for multiclass?
Bhavesh you mentioned clearly this class weights penalizes the false negative what if you want to penalise the false positive rate??
What is the difference between SMOTE and Class_weight?? When to use SMOTE and Class_weight?
as far as i know smote is used to create artificial dataset for minority class. But problem will be for say an image dataset where it will be inaccurate to generate images for minority classes so for that u would need this class_weight method
Hi bhavesh
Where can i find the dataset and Jupiter notebook
github.com/bhattbhavesh91/imbalance_class_sklearn
@@bhattbhavesh91 thanks
Hi can this applied to KNN?
Yes!
@@bhattbhavesh91 thanks...
1:12 it will be logistic regression
Thanks for pointing it out!
true positive is 0 ! so f1 is almost 0 your table has some mistake
hi, when you use cv for optimal weight, why does the weight need to be "x" and "1-x" ? The "balanced" option produces weights that do not sum up to become 1. so why do we use gridsearch to find weights in the range [0,1] ?