Why we typically use dependent sampling to sample from the posterior

Vložit
- čas přidán 29. 08. 2024
- Explains why independent sampling from the posterior is typically impossible and why we are forced to use dependent sampling instead.
This video is part of a lecture course which closely follows the material covered in the book, "A Student's Guide to Bayesian Statistics", published by Sage, which is available to order on Amazon here: www.amazon.co....
For more information on all things Bayesian, have a look at: ben-lambert.co.... The playlist for the lecture course is here: • A Student's Guide to B...


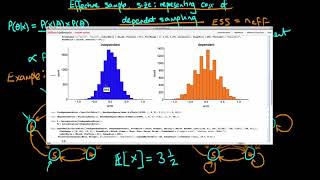
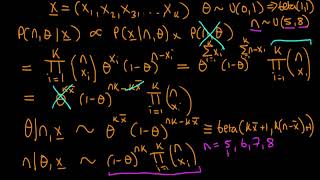





13:30. Would this not be 2? 1/(1/2)? And at 15:05, in the graph, why is P(theta 3 -> theta1) = 4/8, and not P(proposal of theta3 to theta1 = 1/2)*P(accepting it = 4) = 2 = 16/8? Now I assume it is because sum of P leaving the state has to add to 1, however, surely the ratios of the proposals and acceptances would match the ratios of P's leaving any 1 node?
I lost you there towards the end when you show the simulation. When you talk about iterations, what exactly are you iterating over? We start at theta1 from which I do understand that the probability of being anywhere else is 0. But when you move to the 1st iteration, the probabilities change and I'm not able to entirely understand how.
So, is one "iteration" in your simulation shifting a mass from each point to all neighbours according to the transition probability? This seems very computationally expensive, doesn't it?