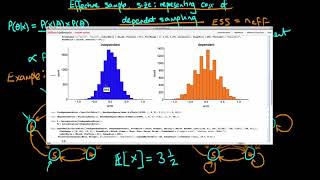
What is the difference between independent and dependent sampling algorithms?

Vložit
- čas přidán 10. 09. 2024
- This video explains the differences between the two main categories of samplers used in applied inference - independent and dependent sampling algorithms.
This video is part of a lecture course which closely follows the material covered in the book, "A Student's Guide to Bayesian Statistics", published by Sage, which is available to order on Amazon here: www.amazon.co....
For more information on all things Bayesian, have a look at: ben-lambert.co.... The playlist for the lecture course is here: • A Student's Guide to B...








Sir - Can you please advice which application you are using to create this beautiful videos ?
Isn't independent sampling only effective when the dimension of data is low? And isn't that why we have to use dependent sampling when the dimension of data gets high? The last example you gave, you said the difference will hold for more complicated model and dependent sampling is much more inefficient; if so, why do we still need use it for high dimensional data?
L C Hi, thanks for your comment. Generally speaking (discounting, for example, antithetic sampling) independent sampling is more efficient than dependent sampling because the informational value of an additional sample is greater for the independent case. Doing independent sampling, however, is typically not possible in applied circumstances whereas in many cases we can nonetheless do dependent sampling (MCMC). Indeed, we gauge the performance of a dependent sampler by comparing its properties (typically, it's autocorrelation) to that of an independent sampler. Hope that helps! Best, Ben
Hi Ben, Thank you so much for your quick response! I do understand that when we can do independent sampling, the informational value of a sample is greater, for the independent sampling case. However, since you said that Independent sampling is typically not possible in applied circumstances. I assume that the applied circumstances imply mostly to the complicated distributions. Thus, does that imply when using independent sampler, the ESS/ActualSampleSize ratio approximates to zero? Thank you for your clarification! Best regards, Lizi
L C Hi Lizi, no problem. By applied circumstances, I mean problems with more than a few parameters. Typically we use dependent sampling in Bayesian inference since, in most cases, we have more than a few parameters which means the posterior distributions cannot be analytically calculated (unless you have conjugate likelihood/prior pairs). For an independent sampler, the effective sample size will be the same as the actual sample size, hence, their ratio will be 1. Hope that helps! Best, Ben