
- 41
- 375 786
Kapil Sachdeva
United States
Registrace 26. 09. 2013
"Work like Hell. Share all you know. Abide by your handshake. Have fun!" - Dan Geer
I saw this on my mentor’s internal profile page some 20 years back, I shamelessly stole it and made it mine .... years later I discovered Dan Geer, the author of this quote ...but it does not matter who said it, rather the key is to assimilate these adages, these words of wisdom in your very being and is equally important to keep them in your sight as the gentle reminder of what is important!
Amongst the many obligations and responsibilities that we all have, the one that remains most dear to me is to keep learning and then sharing what I learned. I have done this for as long as I can remember; very early on in my life, I had accidentally discovered that you learn more when you share what you know. This is one aspect of my life that has been very consistent & the one I cherish the most.
This youtube channel is my new medium of sharing what "I think I know"!
I saw this on my mentor’s internal profile page some 20 years back, I shamelessly stole it and made it mine .... years later I discovered Dan Geer, the author of this quote ...but it does not matter who said it, rather the key is to assimilate these adages, these words of wisdom in your very being and is equally important to keep them in your sight as the gentle reminder of what is important!
Amongst the many obligations and responsibilities that we all have, the one that remains most dear to me is to keep learning and then sharing what I learned. I have done this for as long as I can remember; very early on in my life, I had accidentally discovered that you learn more when you share what you know. This is one aspect of my life that has been very consistent & the one I cherish the most.
This youtube channel is my new medium of sharing what "I think I know"!
Eliminate Grid Sensitivity | Bag of Freebies (Yolov4) | Essentials of Object Detection
This tutorial explains a training technique that helps in dealing with objects whose center lies on the boundaries of the grid cell in the feature map.
This technique falls under the "Bag of Freebies" category as it adds almost zero FLOPS (additional computation) to achieve higher accuracy during test time.
Pre-requisite:
Bounding Box Prediction
czcams.com/video/-nLJyxhl8bY/video.htmlsi=Fv7Bfgxd1I-atZF0
Important links:
Paper - arxiv.org/abs/2004.10934
Threads with a lot of discussion on this subject:
github.com/AlexeyAB/darknet/issues/3293
github.com/ultralytics/yolov5/issues/528
This technique falls under the "Bag of Freebies" category as it adds almost zero FLOPS (additional computation) to achieve higher accuracy during test time.
Pre-requisite:
Bounding Box Prediction
czcams.com/video/-nLJyxhl8bY/video.htmlsi=Fv7Bfgxd1I-atZF0
Important links:
Paper - arxiv.org/abs/2004.10934
Threads with a lot of discussion on this subject:
github.com/AlexeyAB/darknet/issues/3293
github.com/ultralytics/yolov5/issues/528
zhlédnutí: 972
Video


GIoU vs DIoU vs CIoU | Losses | Essentials of Object Detection
zhlédnutí 3,7KPřed 11 měsíci
This tutorial provides an in-depth and visual explanation of the three Bounding Box loss functions. Other than the loss functions you would be able to learn about computing per sample gradients using the new Pytorch API. Resources: Colab notebook colab.research.google.com/drive/1GAXn6tbd7rKZ1iuUK1pIom_R9rTH1eVU?usp=sharing Repo with results of training using different loss functions github.com/...
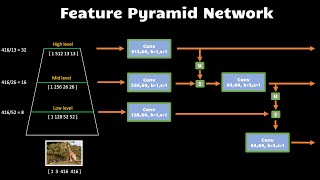
Feature Pyramid Network | Neck | Essentials of Object Detection
zhlédnutí 11KPřed rokem
This tutorial explains the purpose of the neck component in the object detection neural networks. In this video, I explain the architecture that was specified in Feature Pyramid Network paper. Link to the paper [Feature Pyramid Network for object detection] arxiv.org/abs/1612.03144 The code snippets and full module implementation can be found in this colab notebook: colab.research.google.com/dr...

Bounding Box Prediction | Yolo | Essentials of Object Detection
zhlédnutí 8KPřed rokem
This tutorial explains finer details about the bounding box coordinate predictions using visual cues.

Anchor Boxes | Essentials of Object Detection
zhlédnutí 10KPřed rokem
This tutorial highlights challenges in object detection training, especially how to associate a predicted box with the ground truth box. It then shows and explains the need for injecting some domain/human knowledge as a starting point for the predicted box.

Intersection Over Union (IoU) | Essentials of Object Detection
zhlédnutí 3,6KPřed rokem
This tutorial explains how to compute the similarity between 2 bounding boxes using Jaccard Index, commonly known as Intersection over Union in the field of object detection.
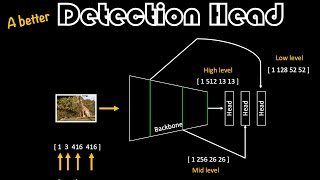
A Better Detection Head | Essentials of Object Detection
zhlédnutí 2KPřed rokem
This is a continuation of the Detection Head tutorial that explains how to write the code such that you can avoid ugly indexing into the tensors and also have more maintainable and extensible components. It would beneficial to first watch the DetectionHead tutorial Link to the DetectionHead tutorial: czcams.com/video/U6rpkdVm21E/video.html Link to the Google Colab notebook: colab.research.googl...
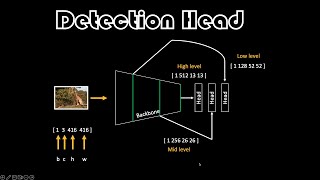
Detection Head | Essentials of Object Detection
zhlédnutí 4,7KPřed rokem
This tutorial shows you how to make the detection head(s) that takes features from the backbone or the neck. Link to the Google Colab notebook: colab.research.google.com/drive/1KwmWRAsZPBK6G4zQ6JPAbfWEFulVTtRI?usp=sharing

Reshape,Permute,Squeeze,Unsqueeze made simple using einops | The Gems
zhlédnutí 4,4KPřed rokem
This tutorial introduces to you a fantastic library called einops. Einops provides a consistent API to do reshape, permute, squeeze, unsqueeze and enhances the readabilty of your tensor operations. einops.rocks/ Google colab notebook that has examples shown in the tutorial: colab.research.google.com/drive/1aWZpF11z28KlgJZRz8-yE0kfdLCcY2d3?usp=sharing
Image & Bounding Box Augmentation using Albumentations | Essentials of Object Detection
zhlédnutí 6KPřed rokem
This tutorial explains how to do image pre-processing and data augmentation using Albumentations library. Google Colab notebook: colab.research.google.com/drive/1FoQKHuYuuKNyDLJD35-diXW4435DTbJp?usp=sharing
Bounding Box Formats | Essentials of Object Detection
zhlédnutí 5KPřed rokem
This tutorial goes over various bounding box formats used in Object Detection. Link the Google Colab notebook: colab.research.google.com/drive/1GQTmjBuixxo_67WbvwNp2PdCEEsheE9s?usp=sharing
Object Detection introduction and an overview | Essentials of Object Detection
zhlédnutí 8KPřed rokem
This is an introductory video on object detection which is a computer vision task to localize and identify objects in images. Notes - * I have intentionally not talked about 2-stage detectors. * There will be follow-up tutorials that dedicated to individual concepts
Softmax (with Temperature) | Essentials of ML
zhlédnutí 3,4KPřed 2 lety
A visual explanation of why, what, and how of softmax function. Also as a bonus is explained the notion of temperature.
Grouped Convolution - Visually Explained + PyTorch/numpy code | Essentials of ML
zhlédnutí 4,4KPřed 2 lety
In this tutorial, the need & mechanics behind Grouped Convolution is explained with visual cues. Then the understanding is validated by looking at the weights generated by the PyTorch Conv layer and by performing the operations manually using NumPy. Google colab notebook: colab.research.google.com/drive/1AUrTK622287NaKHij0YqOCvcdi6gVxhc?usp=sharing Playlist: czcams.com/video/6SizUUfY3Qo/video.h...
Convolution, Kernels and Filters - Visually Explained + PyTorch/numpy code | Essentials of ML
zhlédnutí 2KPřed 2 lety
This tutorial explains (provide proofs using code) the components & operations in a convolutional layer in neural networks. The difference between Kernel and Filter is clarified as well. The tutorial also points out that not all kernels convolve/correlate with all input channels. This seems to be a common misunderstanding for many people. Hopefully, this visual and code example can help show th...
Matching patterns using Cross-Correlation | Essentials of ML
zhlédnutí 1,1KPřed 2 lety
Matching patterns using Cross-Correlation | Essentials of ML
Let's make the Correlation Machine | Essentials of ML
zhlédnutí 1,7KPřed 2 lety
Let's make the Correlation Machine | Essentials of ML
Reparameterization Trick - WHY & BUILDING BLOCKS EXPLAINED!
zhlédnutí 10KPřed 2 lety
Reparameterization Trick - WHY & BUILDING BLOCKS EXPLAINED!
Variational Autoencoder - VISUALLY EXPLAINED!
zhlédnutí 12KPřed 2 lety
Variational Autoencoder - VISUALLY EXPLAINED!
Probabilistic Programming - FOUNDATIONS & COMPREHENSIVE REVIEW!
zhlédnutí 4,7KPřed 2 lety
Probabilistic Programming - FOUNDATIONS & COMPREHENSIVE REVIEW!
Metropolis-Hastings - VISUALLY EXPLAINED!
zhlédnutí 31KPřed 2 lety
Metropolis-Hastings - VISUALLY EXPLAINED!
Markov Chains - VISUALLY EXPLAINED + History!
zhlédnutí 12KPřed 2 lety
Markov Chains - VISUALLY EXPLAINED History!
Monte Carlo Methods - VISUALLY EXPLAINED!
zhlédnutí 4,1KPřed 2 lety
Monte Carlo Methods - VISUALLY EXPLAINED!
Conjugate Prior - Use & Limitations CLEARLY EXPLAINED!
zhlédnutí 3KPřed 2 lety
Conjugate Prior - Use & Limitations CLEARLY EXPLAINED!
Posterior Predictive Distribution - Proper Bayesian Treatment!
zhlédnutí 5KPřed 3 lety
Posterior Predictive Distribution - Proper Bayesian Treatment!
Sum Rule, Product Rule, Joint & Marginal Probability - CLEARLY EXPLAINED with EXAMPLES!
zhlédnutí 5KPřed 3 lety
Sum Rule, Product Rule, Joint & Marginal Probability - CLEARLY EXPLAINED with EXAMPLES!
Noise-Contrastive Estimation - CLEARLY EXPLAINED!
zhlédnutí 10KPřed 3 lety
Noise-Contrastive Estimation - CLEARLY EXPLAINED!
Bayesian Curve Fitting - Your First Baby Steps!
zhlédnutí 6KPřed 3 lety
Bayesian Curve Fitting - Your First Baby Steps!
Maximum Likelihood Estimation - THINK PROBABILITY FIRST!
zhlédnutí 6KPřed 3 lety
Maximum Likelihood Estimation - THINK PROBABILITY FIRST!
Great video!
I have 2 questions. How are the 1X1 and 3X3 CNN used trained to obtain the weight parameters? Also shouldn't 3X3 with stride 1 change the dimension, though it keeps the number of channels the same the size of the output feature would have changed and reduced by 2
Your videos are amazing, very clear and concise explanations!
This is the best series I have watched on explanation of object detection algorithms. Also, your approach of asking fundamental questions like "Why in this case, a metric of evaluation can't be used as a loss function" and many more such questions you addressed were so insightful. Really grateful for the efforts you've put in here. Thank you. 🙏🙏
At 11:02, instead of "the first rows of the first four channels will be for box coordinates", do you intend to say "the first cells of the first four channels will be for box coordinates"?
Thank you very much for your video. But I have a question: when g(x) is a function U(a,b), the probability of choosing Y which obeys g(x) is the same for all Y in (a,b). But when the bounding function is Gaussian or something else (i.e. when simulating g(x) we cannot guarantee the probability of selecting each point is the same), does it affects the probability of selecting X which obeys f( x) ? ( Because if the simulation of Y is not equivalent then even if the next steps are effective, we cannot guarantee that we give equal chances to all points X when starting before "reject or accept")
Simply beautiful ❤️
Thanks for the lecture sir! I have a question at 4:54, how did you expand that E[log_p_theta(x)] into Integral(q(z|x)log_p_theta(x)dz)? Thanks!
Thank you so much, First I read the 1st chapter of this book and then I listened to your video. You gave a superb explanation and cleared all doubts. Thanks for your community service :)
Amazing explanation!
Thank you! One request -- can you explain the reason behind the equivalence between assuming that the target variable is normally distributed and the assumption that the errors are normally distributed. While I understand that the two assumptions are simply the two sides of the same coin, the mathematical equivalence between them appeared to me like something that is implicitly assumed in moving from part 2 video to part 3 video.
Very articulated explanations, really appreciate it! thanks!
❤❤🙏🏽🙏🏽🙏🏽 thanks and subscribed
Thank you for your hard work, which enables us to understand crystal clear. Thanks a lot ❤❤❤
Hi, I have got micrsoft form recognizer api which gives bounding box of 8 coordinates for a given class, how to draw bounding box using that. for eg: bounding_regions=[BoundingRegion(page_number=1, polygon=[Point(x=33.0, y=496.0), Point(x=169.0, y=496.0), Point(x=168.0, y=532.0), Point(x=33.0, y=532.0)])] they haven't provided in the documentation as well, if you could help, I would appreciate it. I have converted it into list like this [33.0, 496.0, 169.0, 496.0, 168.0, 532.0, 33.0, 532.0] but don't how to plot.
Excellent
Thank you for these very clear and visually efficient explanations. I'll make sure to use these concepts in my PhD work !
I thought temperature was like getting a fewer and saying random things:)
Depends on the context. Here it is about logits. In LLM apis it is to control the stochasticity/randomness.
The best! Thank you sir
At 5:01 could you please explain why is it [1,5] and not [5,1]? Shouldn't the coordinates be in (x,y) format?
No the coordinates are in [y,x] … nothing specific about it as such, just a convention used in all object detection models.
Thank you a lot for your videos! Selection of subjects in your series is excellent, every tutorial offers very interesting information.
🙏
One stupid question here, Why we were interested in finding max joint probability, in the first place?? were there any other way to find w and beta??
It learns the parameter right?
At 6:39, the distribution p_\theta(x|z) cannot have mean mu and stddev sigma as the mean and std dev live in the latent space (the space of z) and x lives in the input space.
Watching your videos keeps reminding me of the phrase “a picture is worth a thousand words”, to which I want to add “ a great picture is worth thousands in gold”. Many times I had to freeze the video to let a particular moment sink in, because I couldn’t believe the insight that picture brings out . ❤❤❤
I am grateful to your lectures ❤ what a wonderful service you’ve done to all the learners
So, in-depth and with those visualization it is a grate learning experience
In real life we don't know Target distribution - f(x). How did you calculated alpha for various sample points ? f(Xt+1)/f(Xt)
We are okay with imperfections as long as they are useful to us ... great wisdom🙏
Amazing. Thanks for posting.
At the 4:45 mark, how did you expand the third term Expectation into its integral form in that way? How is it an "expectation with respect to z" when there is no z but only x?
my feedback is that this is amazing!!! wish my ML prof taught this :( this truly is one of the few videos that breaks the sum rule, product rule, join and marginal probability down so well
Great video; thank you :)
How you plot this? which software you are using?
THANK TYOY SO MUCH
I am worried that he hasn't uploaded videos in 7 months.... is everything alright?
He is really sorry about it and feels miserable that he is not being of service to others; … some diagnosis reveals that he is suffering from overthinking and laziness. 😢
Amazing lectures, thank you so much! I was wondering at 12:07 the partial derivatives of E wrt w_i (in the right panel), shouldn't those be the partial derivatives of ys and not Es?
No it is E, the error function. Our goal is to minimize the error.
Thank you, very good overview. You must be having thorough understanding of many object detection models to deliver this kind of overview. I have one question (only for discussion): How it is "clear" (1:22) that object detection is difficult task for machines? I think it is important to mention why the problem is difficult (challenges) to solve from computer vision point of view. You did mention a couple of challenges at 10:40 but these are w.r.to DL approach.
Difficult if you compare it to classification problem. Where an image either belongs to class 1 or classes x. I called it difficult because of 3 reasons - you have to do localization and classification and the fact that the number of objects are variable.
You just saved a college student living in South Korea! Thanks for amazing visualization and explanations!
🙏
best MCMC video I have seen
🙏
1:31 how do we not know how to sample as the distribution function is already given and you also plotted it ?
Somehow it is a common confusion for many. Knowing a distribution function can only help you find the probability of a sample. Sampling from a function is a different task. Sampling means asking your computer to generate a sample. Sampling makes use of random number generator. Now your random number generator (algorithm) is to behave in such a way that the samples (random numbers) are generated in accordance with their prob distribution. Some samples are supposed to be more (the one with high prob) and some less. This is why various sampling algos/techniques are created. Your computer by default can give uniform random numbers. Most of the algorithms directly or indirectly manipulate the result of uniform random number generator.
thanks
🙏
This is pure gold ❤
🙏
5:35 Bayes Rule ... intractable computation.
Clear and easy to understand compared to other videos throwing lots of math formula at the begiinning. Great work! subscribed your channel
🙏
Thank you so much sir for the amazing explanation and visualization.
🙏
If done with UNet, it won't require upsampling as we concatenate the layers right?
Just Mind-blowing loved the way you explained concepts and slowly built on it, that's how inventions and human mind works and mathematics is just a tool to realize/record complex ideas. Other lectures directly jump into maths without explaining the idea.
🙏
Still you didn’t explain the need of CPDF, also you told that we want to get rid of evaluating integral therefore we want something…? What CPDF , but CPDF is integral of pdf
Spectacular 👏
🙏