If you think I deserve it, please consider liking the video and subscribing for more content like this :) Some corrections in the video: 2:38 the dimensions of each one hot encoded vector is max_sequence_length x vocab_size (I mentioned the latter incorrectly in the video)
Great video! However i believe that the multiple heads generate a separate set of qkv, rather than splitting the vectors up between heads. This does enable the model forming different perspectives on the input, but does not introduce a "batch" dim
Absolutely amazing series! Thank you so much for explaining everything over these videos and especially the code and visual examples! I'm very excited to learn about the decoder when you're ready to cover it. Perhaps for the descriptions of Q, K, and V, it might help to distinguish V not as "what we actually have" (I think) and instead as "what we actually provide". So "what we want," "what we have to offer," and "what we actually provide." That's at least how I understand it.
Thanks so much for commenting and super happy to hear you are enjoying the series! And yea, explaining Q K V is a lil challenging and your interpretation makes sense. It’s just a lil strange to explain since in practice , these tensors are stacked together, making them hard to distinguish.
With every new video from your Transformer series, I still keep learning something new, especially in clarifying some aspect that I didn't fully comprehend before.
You are a very unique tutor. I love the way you explain everything from start in your every video. It helps us understand and learn the concept in so much depth that it won't be easy to ever forget these concepts
we scale weights by 1/sqrt(d_k) to avoid variance problems (q, k have variance of roughly 1. so q @ k.T will have variance of d_k (head_size). in order to make its variance 1 we divide by sqrt(d_k)) - otherwise softmax will have really high values (higher values, when passed into the softmax function, will converge to a one-hot vector, which we want to avoid :))
Yea. Scaling does definitely stabilize these values. I have spoken more about this with some code in the “Transformers from scratch” playlist if interested in checking out too :)
Well nicely structured and clearly explained. Thanks a lot. You deserve lot more subscribers. Once again thanks for putting so much time and efforts for making this playlist.
Thanks, very helpful. For me, I go over various sections more than once which is ok on line but would irritate you and others in a live class--but it helps me learn. What an exciting time to be doing neural networks after decades of struggle.
Thank you so much for this sir. Learning so much here. I know many might disagree with the philosophical aspect of Mind, and dont mean to shoe-horn in but, I think these Transformer Networks are humanity's successful building of a Mind. Expressing intangible thought into semi-tanglible objects that one can piece together to wind up a thinking machine. Yet doesnt exist in the same 3D plane as physical objects, as Math doesnt exist in this plane, its in the Thought/Mind non-spacial dimension.
Ngl There Are Still Quite a Few Things That I Don't Exactly Understand Maybe Becuz English Is Not My First Language However I Think As We Go Practical I'll Understand Better, And I Just Can't Thank You Enough For This Series Brother, Thank You Sooo Much 🖤
Hi. This video is an extremely perfect one. at @5:30 the dimension of output from the qkv linear layer is 1536*max_seq_len? and each qkv matrix is 512*max_seq_len .
Hi Ajay, thank you so much for these transformer breakdowns, they're great! One thing that is confusing me about the 'initial encodings' step, whereby you transform the input tokens to their respective one-hot vectors; your diagram shows that as a SLx SL vector. My question: is this encoding trying to preserve positional information or is it trying to uniquely identify the token? I had thought it was the latter, which would mean it shouldn't be SL x SL, it should be SL x Vocabulary such that the one hot encodings can represent any token in the 'language' not just those in the input sequence.
Thanks a mil for your explanations! I have a little request. Do you think you could share the little "not so complicated" diagram you showed at the beginning of the video? Thanks a mil!!!!
I think i finally understand transformers. Especially the qkv part. In the first skip connection you add the positional encodings only, but i the original drawing it seems they are adding the (positional+base) embeddings in the residual connection. Can you please elaborate about that?
Two questions for the Input: 1) If you do One Hot Encoding: Is the matrix size really "Max Sequence Length x Max Sequence Length" - or shouldn't it be "Max Sequence Length x Dict Length"? 2) Is it really necessary to do One Hot Encoding for the Input? I mean the words are encoded/embedded in this 512 dimensional vectors, so it doesn't matter how they are - initially - referenced, no?
1. Correct. Good catch. It’s in the pinned comment as well 2. Yea in code, you don’t really need to explicitly one got encode. This is implemented via a torch embedding lookup. But I just explicitly expressed what nn.Embedding effectively does. Again, good catch
Thank you for this great explanation. I think the multi-head explanation is inverted ( on purpose for simplicity i guess) But i guess the idea is to start with a 64 dimensional QKV and then concatenate them to n heads in your case it s 8 heads. Also this way we can have the possibility to concatenate them or just get the mean of the 8 heads.
Thank you for watching! Yea I am trying to make these vectors more intuitive. But like I mentioned in the video, they are typically coded out in one unit I.e the query key and value tensors are technically treated as one large tensor. Hopefully this will be more clear as I demonstrate code in the next video
Hi CodeEmporium Team , Thanks for such great content. One question I have - When we use Transformers Encoder to encode any sequence to generate embeddings what loss function does transformer uses. For e.g. I am using Transformer Encoder to encode a sequence of user actions in a user session to generate embeddings to be used in my recommender system. Kindly answer
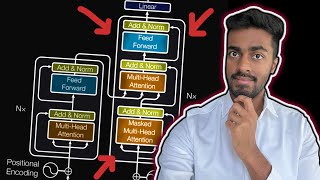
In the summarized diagram there is no “skip connection” for positional encodings but for values. Just after you explain residual connections you tell about an add operation and I then expected that that would be the value, because that is what is in the summarized diagram, but in your expanded diagram it is the positional encoding. And you never have a + for the value in your expanded diagram. What does this mean? 1. Is the summarized diagram leaving out details (forgetting the positional encoding skip connection) or 2. did you accidentally forget to draw in the value skip connection or 3. did you confuse values with positional encodings because the expansion is so huge? I was very confused about that part. But very nice presentation overall!
thanks for the video. I have a question about Wq, Wk and Wv. you mentioned that Wq is like the encoded original input 'My name is Ajay'. Then what about the Wk and Wv, as you mentioned Wk is what can it offer and Wv is what actually offered. does Wk, and Wv also represent 'My name is Ajay'? Thank you
Not quite. The traditional batch dimension is one thing and each attention head is another. Traditional batch dimension has no interactions - they are different examples as you alluded to. The different heads in multi attention Are similar in the sense they perform parallel operations for the most part. However, they eventually interact with each other. I can see how my words were confusing . Apologies here
Hello some one please help me if my max sequence length is different for input and output. For example if I am applying this text summarising. The input length of text for encoder is different which 4 times the summary length so where should I change the max sequence length after multi head attention of encoder or after normalisation or after feed forward network. Please suggest idea about it.
Am I being dumb or do you need to perform a values = values.permute((0, 2, 1, 3)).reshape((batch_size, max_sequence_length, 512)) instead of just a reshape? The thing is this would not put the words back together in the right order after multi-head-attention, would it? Some code I ran to test this: def f(x): ... return x.reshape((x.shape[0], x.shape[1], 8, -1)).permute((0, 2, 1, 3)).reshape((x.shape[0], x.shape[1], -1)) # compact version of the shape / ordering transforms happening in attention (attention itself doesnt change the shape: initial_v.shape = values.shape) ... >>> def g(x): ... return x.reshape((x.shape[0], x.shape[1], 8, -1)).permute((0, 2, 1, 3)).permute((0, 2, 1, 3)).reshape((x.shape[0], x.shape[1], -1)) ... >>> v = torch.arange(120) >>> v = v.reshape((1, 3, 40)) >>> torch.all(v == f(v)) tensor(False) >>> torch.all(v == g(v)) tensor(True)
No dumb at all; in fact you caught an error that I had been stumped on for a while. Someone pointed this exact issue on GitHub and I corrected it. So the repo code for transformer.py (which is constructed completely in a video later in this series) should have the correct working code. I was coding along the way and didn’t catch this error early on. But great catch and I hope as you watch the rest of the series, it becomes super clear
I was able to nod along and pretend I understood until 19:14. "We actually execute all of these kinds of roles multiple times over [...] like 12 times [...] cascaded one after the other". Do you to say that the entire block is composed with itself? I'm struggling to understand why the encoder would be applied like so: (f (f (f (f (f (f (f (f (f (f (f (f x)))))))))))), or f^12(x). Is the dimensionality of the embedding decreasing with each step, like the gradual down-sampling an image in a diffusion model? Or is it something else? Is there any intuition here?
It’s more like the encoder units are cascaded and applied one after another. So the output of the first encoder will be fed to the input of the second encoder and so on. The dimensionality of the embeddings remain the same after each step. If this was a lil confusing, I’ll be illustrating the code in my next video that should hopefully make this clear.
@@CodeEmporium It must be the case that the attention mechanism can capture increasingly abstract constituents of the input sequence through nesting/composition. Or at least hierarchical in terms of locality, if not true abstraction. Sort of like chunking in the human brain. Otherwise the weights of the feed-forward network and the parallel attention blocks would be able to capture the information through training alone. So if I say "The big red dog walked along the winding path", I can see the first application of the encoder attending to and aggregating the concepts of "red dog" and "winding path". Then subsequent applications could zoom out and find dependencies between [red-dog] and [winding-path] in order to focus on the verb "walked", presumably associating that with the dog as a subject rather than the path. That helps me get past a mental block I've had. I could accept that weight randomization, dropout and the loss function would pressure the attention heads to focus on different parts of the sentence, as is the case with any other form of regression. However I couldn't for the life of me understand how it handled abstraction. Thanks for taking the time to make your drawing precise, I think I"ll do the same as an exercise. EDIT: I also just realized that you could unroll the recurrent application to form a static multi-layer encoder of one application. It's the classic time-space trade-off. And because there's a placeholder token for the fixed-length sequences, that means that dimensionality is baked into the architecture and can effectively vary. Theoretically you could use techniques similar to dropout/replacement in order to force the network to behave like a traditional down-sampling encoder, bottleneck and all.
Yep. I believe so. I have explained more about these in my playlist called “Transformers from scratch” the link is in the description if you are curious about other details :)









If you think I deserve it, please consider liking the video and subscribing for more content like this :)
Some corrections in the video: 2:38 the dimensions of each one hot encoded vector is max_sequence_length x vocab_size (I mentioned the latter incorrectly in the video)
You got it. This is wonderful. Finally someone has taken the time to explain transformers in the right level of detail.
Recommend you post-annotate the vid
haha, I was going to leave a comment, but I guess already caught.
Great video! However i believe that the multiple heads generate a separate set of qkv, rather than splitting the vectors up between heads. This does enable the model forming different perspectives on the input, but does not introduce a "batch" dim
A hidden gem on youtube, these explanations are GOATED. Thank you!
Thanks so much for commenting and watching! :]
Wow ! Excellent explanation ! Couldn't find this content anywhere except your channel. Thanks
Physics students pondering the forth dimension
Computer Scientists casually using 512 dimensions
I have struggled to find a good explanation of transfomers and your videos are just amazing. Please keep releasing new content about AI.
Absolutely amazing series! Thank you so much for explaining everything over these videos and especially the code and visual examples! I'm very excited to learn about the decoder when you're ready to cover it.
Perhaps for the descriptions of Q, K, and V, it might help to distinguish V not as "what we actually have" (I think) and instead as "what we actually provide". So "what we want," "what we have to offer," and "what we actually provide." That's at least how I understand it.
Thanks so much for commenting and super happy to hear you are enjoying the series! And yea, explaining Q K V is a lil challenging and your interpretation makes sense. It’s just a lil strange to explain since in practice , these tensors are stacked together, making them hard to distinguish.
With every new video from your Transformer series, I still keep learning something new, especially in clarifying some aspect that I didn't fully comprehend before.
Super happy this is the case since that is the intention:)
This is a very valuable diagram / cheatsheet for any AI practictioner. Thanks for the excellent work. Great video series.
This is a superb explanation! Your videos are immensely helpful, and are undoubtedly the best on YT.
bro you made me cry again. Thank you for this wonderful content
:) thanks a ton for the kind words. And for watching !
Thanks really very helpful resource for me!
Keep rocking Ajay.
You are truly amazing! Thank you so much for your well-elaborated explanation.
You are very welcome. And thanks for the thoughtful words
You are a very unique tutor. I love the way you explain everything from start in your every video. It helps us understand and learn the concept in so much depth that it won't be easy to ever forget these concepts
This means a lot. Thank you for the kind words! I try :)
we scale weights by 1/sqrt(d_k) to avoid variance problems (q, k have variance of roughly 1. so q @ k.T will have variance of d_k (head_size). in order to make its variance 1 we divide by sqrt(d_k)) - otherwise softmax will have really high values (higher values, when passed into the softmax function, will converge to a one-hot vector, which we want to avoid :))
Yea. Scaling does definitely stabilize these values. I have spoken more about this with some code in the “Transformers from scratch” playlist if interested in checking out too :)
Absolutely the best detailed and visual explanations. None better.
Thanks for the kind words! Hope you check the rest of the playlist “Transformers from Scratch “ out !
You have a talent for reducing complex issues to the essentials and also illustrating them super. I was able to learn so much. Thank you for that! 🤓
Well nicely structured and clearly explained. Thanks a lot. You deserve lot more subscribers. Once again thanks for putting so much time and efforts for making this playlist.
Thanks so much! I appreciate the kind words here
Thank you so much! I finally have an intuition on how encoders work thanks to you😀
The best explanation on internet. Thank you. Keep it up!!
This is wonderful presentation! I finally understand more deeply about transformer. Thanks!
amazing work
Hello Ajay, another awesome video! I may have missed some parts. May I ask why running this 12 times as you said in the last part of video? Thanks.
Thanks, very helpful. For me, I go over various sections more than once which is ok on line but would irritate you and others in a live class--but it helps me learn. What an exciting time to be doing neural networks after decades of struggle.
Thanks so much for commenting! And yes what a time to be alive :)
Thank you so much for this sir. Learning so much here.
I know many might disagree with the philosophical aspect of Mind, and dont mean to shoe-horn in but, I think these Transformer Networks are humanity's successful building of a Mind. Expressing intangible thought into semi-tanglible objects that one can piece together to wind up a thinking machine. Yet doesnt exist in the same 3D plane as physical objects, as Math doesnt exist in this plane, its in the Thought/Mind non-spacial dimension.
Hats off, man.
Good One Ajay
Ngl There Are Still Quite a Few Things That I Don't Exactly Understand Maybe Becuz English Is Not My First Language However I Think As We Go Practical I'll Understand Better, And I Just Can't Thank You Enough For This Series Brother, Thank You Sooo Much 🖤
-----> BERT -------> 👏👍
Haha clever. Thanks so much!
Hi. This video is an extremely perfect one.
at @5:30 the dimension of output from the qkv linear layer is 1536*max_seq_len? and each qkv matrix is 512*max_seq_len .
Best explanation i ever see, really
Thanks so much for commenting!
Hi Ajay, thank you so much for these transformer breakdowns, they're great! One thing that is confusing me about the 'initial encodings' step, whereby you transform the input tokens to their respective one-hot vectors; your diagram shows that as a SLx SL vector. My question: is this encoding trying to preserve positional information or is it trying to uniquely identify the token? I had thought it was the latter, which would mean it shouldn't be SL x SL, it should be SL x Vocabulary such that the one hot encodings can represent any token in the 'language' not just those in the input sequence.
This video is really phenomenal! Thanks for all the hard works! Is it possible for you to share your diagram with us? 😀
why is the embedding size max_seq_len X max_seq_len ? shouldn't it be max_seq_len X vocab_sizze
Thanks a mil for your explanations! I have a little request. Do you think you could share the little "not so complicated" diagram you showed at the beginning of the video?
Thanks a mil!!!!
I think i finally understand transformers. Especially the qkv part.
In the first skip connection you add the positional encodings only, but i the original drawing it seems they are adding the (positional+base) embeddings in the residual connection. Can you please elaborate about that?
I used think that all the heads take entire feature vector of token as input.
Now I understood it just takes part of a feature vector
This is great! Can you please share the encoder arch diagram file you are explaining here. please....
Two questions for the Input:
1) If you do One Hot Encoding: Is the matrix size really "Max Sequence Length x Max Sequence Length" - or shouldn't it be "Max Sequence Length x Dict Length"?
2) Is it really necessary to do One Hot Encoding for the Input? I mean the words are encoded/embedded in this 512 dimensional vectors, so it doesn't matter how they are - initially - referenced, no?
1. Correct. Good catch. It’s in the pinned comment as well
2. Yea in code, you don’t really need to explicitly one got encode. This is implemented via a torch embedding lookup. But I just explicitly expressed what nn.Embedding effectively does. Again, good catch
can you do a deep dive into the embedding transform?
The first layer where you talked about MAX_SEQ_LEN , Does that mean length of each one hot encoded vector is equal to vocab size.
Thank you for this great explanation. I think the multi-head explanation is inverted ( on purpose for simplicity i guess)
But i guess the idea is to start with a 64 dimensional QKV and then concatenate them to n heads in your case it s 8 heads. Also this way we can have the possibility to concatenate them or just get the mean of the 8 heads.
Thank you for watching! Yea I am trying to make these vectors more intuitive. But like I mentioned in the video, they are typically coded out in one unit I.e the query key and value tensors are technically treated as one large tensor. Hopefully this will be more clear as I demonstrate code in the next video
Hi CodeEmporium Team , Thanks for such great content. One question I have - When we use Transformers Encoder to encode any sequence to generate embeddings what loss function does transformer uses. For e.g. I am using Transformer Encoder to encode a sequence of user actions in a user session to generate embeddings to be used in my recommender system. Kindly answer
In the summarized diagram there is no “skip connection” for positional encodings but for values. Just after you explain residual connections you tell about an add operation and I then expected that that would be the value, because that is what is in the summarized diagram, but in your expanded diagram it is the positional encoding. And you never have a + for the value in your expanded diagram. What does this mean? 1. Is the summarized diagram leaving out details (forgetting the positional encoding skip connection) or 2. did you accidentally forget to draw in the value skip connection or 3. did you confuse values with positional encodings because the expansion is so huge? I was very confused about that part. But very nice presentation overall!
Thank you very much!
You are very welcome!
can you make a video on vision transformers please
Thank you! What do you use to make your drawings and record your setup?
thanks for the video. I have a question about Wq, Wk and Wv. you mentioned that Wq is like the encoded original input 'My name is Ajay'. Then what about the Wk and Wv, as you mentioned Wk is what can it offer and Wv is what actually offered. does Wk, and Wv also represent 'My name is Ajay'? Thank you
Your video is 99.9% informative, please provide the image you are showing to make it 100%
The image is in the GitHub repository. Link is in the description of the video
@@CodeEmporium sir, i checked each and every word in your github, i didnt find it sir. can you please take your time and provide the link to it sir?
can i understand the heads here as the kernels in CNN
Does anyone know where the drawing in the video?
I really need that to take a deeper look myself
Sir plz start yolov8 plz
great
6:40 if you're implying that the batch dims communicate with eachother, that's wrong as far as I know.
Not quite. The traditional batch dimension is one thing and each attention head is another. Traditional batch dimension has no interactions - they are different examples as you alluded to. The different heads in multi attention
Are similar in the sense they perform parallel operations for the most part. However, they eventually interact with each other. I can see how my words were confusing . Apologies here
@@CodeEmporium Thanks for the clarification!
Shouldn't it be MAX SEQENCE LENGTH x VOCAB SIZE?
Even I think so at the time of input
Hello some one please help me if my max sequence length is different for input and output. For example if I am applying this text summarising. The input length of text for encoder is different which 4 times the summary length so where should I change the max sequence length after multi head attention of encoder or after normalisation or after feed forward network. Please suggest idea about it.
do i need to decoder in image classification task, or i just need to encoder part ?
Thanks so much for this video, just wondering if there's a difference in encoding in the Vision Transformer model
I need to take a look at the vision transformer. Wouldn’t want to give you half baked knowledge on this
@@CodeEmporium Cool looking forward to it if it gets released!
Am I being dumb or do you need to perform a values = values.permute((0, 2, 1, 3)).reshape((batch_size, max_sequence_length, 512)) instead of just a reshape? The thing is this would not put the words back together in the right order after multi-head-attention, would it? Some code I ran to test this:
def f(x):
... return x.reshape((x.shape[0], x.shape[1], 8, -1)).permute((0, 2, 1, 3)).reshape((x.shape[0], x.shape[1], -1)) # compact version of the shape / ordering transforms happening in attention (attention itself doesnt change the shape: initial_v.shape = values.shape)
...
>>> def g(x):
... return x.reshape((x.shape[0], x.shape[1], 8, -1)).permute((0, 2, 1, 3)).permute((0, 2, 1, 3)).reshape((x.shape[0], x.shape[1], -1))
...
>>> v = torch.arange(120)
>>> v = v.reshape((1, 3, 40))
>>> torch.all(v == f(v))
tensor(False)
>>> torch.all(v == g(v))
tensor(True)
No dumb at all; in fact you caught an error that I had been stumped on for a while. Someone pointed this exact issue on GitHub and I corrected it. So the repo code for transformer.py (which is constructed completely in a video later in this series) should have the correct working code.
I was coding along the way and didn’t catch this error early on. But great catch and I hope as you watch the rest of the series, it becomes super clear
great content!!!!!!!!
Thank you so much!
Thanks so much
I was able to nod along and pretend I understood until 19:14. "We actually execute all of these kinds of roles multiple times over [...] like 12 times [...] cascaded one after the other". Do you to say that the entire block is composed with itself? I'm struggling to understand why the encoder would be applied like so: (f (f (f (f (f (f (f (f (f (f (f (f x)))))))))))), or f^12(x).
Is the dimensionality of the embedding decreasing with each step, like the gradual down-sampling an image in a diffusion model? Or is it something else? Is there any intuition here?
It’s more like the encoder units are cascaded and applied one after another. So the output of the first encoder will be fed to the input of the second encoder and so on. The dimensionality of the embeddings remain the same after each step. If this was a lil confusing, I’ll be illustrating the code in my next video that should hopefully make this clear.
@@CodeEmporium It must be the case that the attention mechanism can capture increasingly abstract constituents of the input sequence through nesting/composition. Or at least hierarchical in terms of locality, if not true abstraction. Sort of like chunking in the human brain. Otherwise the weights of the feed-forward network and the parallel attention blocks would be able to capture the information through training alone.
So if I say "The big red dog walked along the winding path", I can see the first application of the encoder attending to and aggregating the concepts of "red dog" and "winding path". Then subsequent applications could zoom out and find dependencies between [red-dog] and [winding-path] in order to focus on the verb "walked", presumably associating that with the dog as a subject rather than the path.
That helps me get past a mental block I've had. I could accept that weight randomization, dropout and the loss function would pressure the attention heads to focus on different parts of the sentence, as is the case with any other form of regression. However I couldn't for the life of me understand how it handled abstraction.
Thanks for taking the time to make your drawing precise, I think I"ll do the same as an exercise.
EDIT: I also just realized that you could unroll the recurrent application to form a static multi-layer encoder of one application. It's the classic time-space trade-off. And because there's a placeholder token for the fixed-length sequences, that means that dimensionality is baked into the architecture and can effectively vary. Theoretically you could use techniques similar to dropout/replacement in order to force the network to behave like a traditional down-sampling encoder, bottleneck and all.
Is it 12 or 6? I think we use 6 encoders and not 12.
Might you consider creating a Discord guild?
Ajay I guess dk is 64. And square root of it is 8. It is done to stable the gradients.
Yep. I believe so. I have explained more about these in my playlist called “Transformers from scratch” the link is in the description if you are curious about other details :)
2:38: Do you mean Max Sequence Length x Dictionary Size? (the one-hot vectors must be able to encode every single token in the dictionary)
Yes. Thanks for pointing this out
@@CodeEmporium You're welcome. Thanks a lot for the videos, by the way, they're super helpful, and you're a great teacher
Looking forword to get simillar video for decoder.
Coming up very soon
@@CodeEmporium Exited about that.
A request, Please explain over there how we get the key & value from encoder output, that we put in decoder.
you are the best 🥵❣
Not so painstakingly in not so complicated diagram :3
lol
houu ơ du