Video není dostupné.
Omlouváme se.
An introduction to Gibbs sampling

Vložit
- čas přidán 14. 08. 2024
- Uses a bivariate discrete probability distribution example to illustrate how Gibbs sampling works in practice. At the end of this video, I provide a formal definition of the algorithm.
This video is part of a lecture course which closely follows the material covered in the book, "A Student's Guide to Bayesian Statistics", published by Sage, which is available to order on Amazon here: www.amazon.co....
For more information on all things Bayesian, have a look at: ben-lambert.co.... The playlist for the lecture course is here: • A Student's Guide to B...
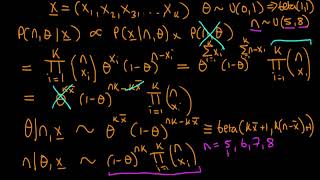








Detailed examples always make concepts more clear. Thank you for helping me in understanding Gibbs smpling properly for the first time!
Hi, thanks for your comment - glad to hear the video was useful. Cheers, Ben
@@SpartacanUsuals I lost myself in the first half of my course and fixed it within 10 mins in your video. Things can be better explained without fancy maths.
@@fouriertransformationsucks438 I just cannot understand lecturers/teachers not giving explicit examples of a new concept be it an algorithm, a probability distribution, a derivation of some probability law or whatever without first fully conceptualising it intuitively to the students by giving a concrete example or a clear visual representation. This is what Mr. Lambert has done here and if my teacher or your teacher did the same it would eliminate so much struggle, frustration and wasted time and energy. It's just so frustrating and disheartening because it's largely unnecessary. Lecturing at College/University institutions is one of the only professions I can think of whereby practitioners receive absolutely no training whatsoever.
Anyway, rant over. Thank you Ben Lambert for the great lesson!
Thanks a lot Ben, I'm in a scenario where I had a sudden drop in quality of lecturing at my University (graduate study in what the cool kids are now calling data science) and now have to rely on online sources to understand the material.
I reviewed a number of Gibbs Sampling Videos before reaching yours and I got to say that the decision to start with the example, followed by the simulation of the example and ending with the formal definition was a great way to teach it. The careful tone, wording and pace of speaking was excellent as well.
Much appreciated and going to be putting your name amongst the top of my go-to education videos for the Bayes space.
This is the best explanation of gibbs sampling I could find and it really makes things clear by walking through an example step by step. This was really helpfull, so thank you!
Brilliantly taught. This is really the only accessible introduction to Gibbs sampling anywhere.
Excellent Introduction to Gibbs sampling. This is the first time in years that I got a clear insight into Gibbs sampling
This is really an explicit tutorial. Thank you a lot!
Your are the best teacher I've ever "had"
Thank you!! Really appreciating your Bayesian videos. Super helpful!
Great visualization! I was able to understand the concept right away with this.
Thank you!! I finally understand Gibbs sampling!!
you're literally my savior... thank you a lot!
You are such a tremendous explainer!
THANKS!! Finally a clear and intuitive explanation! Much appreciated! :D
Fantastic video! Love the use of actual examples
Excellent! even without the animation your explanation is spot on. Most helpful for me was the part before the animation where you actually showed the joint and conditional probability tables. Thereafter everything was crystal clear. Just a side note: at 15:00 did you forget to add superscript 't' over theta3 ?
btw its a fantastic vedio man. it was so helpfull for me✨
Best example I've ever seen
Exceedingly clear! Love it!
Fantastic video!
YOU ROCK! I FINALLY UNDERSTOOD IT! THANK YOU!
Thank you for this detailed video.
Very well explained. Thank you !
Great video.
The first step seems extraneous. There is no need to sample theta_1, theta_2 AND theta_3 in the initialization step (since you only use one of the RVs as input at the first iteration). It seems it would be better just to sample an arbitrarily chosen RV from its univariate distribution, and then use that as input t the first iteration.
this was helpful, thanks!
Thank you Very clear example
Very clear, good work!
One of the best intros to Gibbs Sampling - an easy-to-follow example, visualisation and very approachable theory mentioning points to keep in mind - that I've seen. Will be getting your book, so just take my money already!
P.S: Do you have any Python-specific implementations for your book? I saw that it uses R?
Thank you!
Thank you! Love this channel
what does exploring posterior space mean? Does it mean exploring the actual densities?
Really good lecture. Please try to remove the echo !
15:32... t is missing in theta3 expression (in case of theta1,2,3 are stored in array)
excellent
So the algorithm runs until A_T ~ P(A|B_T-1) and B_T ~ P(B|A_T) ?
Thanks a ton Ben.
Thank you very much for this! :)
how you choose whether A = 0 or A = 1? The same question for B
Same question, maybe I am misunderstanding that step here. E.g. after the first step you chose A = 1 and you are at (1, 0), then P(B|A = 1) is 2/3 for B=0 and 1/3 for B=1. I thought you then choose B = 1 because that outcome is more probable? But then you will always get the same coordinate (1, 0). And you actually chose B = 1 in the video and avoided the problem. But why would you go for B=1 at that step? It will be great if you can shed more light on that!
I'm having the same question
@@mengxing6548 same question
Do you need to know the distribution before hand by calculating based on sample data? Then you find the true distribution from that data?
It seems the two horses are not independent. Because P(A,B) is not equal to P(A)*P(B).
Hi Ben. Thanks for making this video. Works like yours is always very helpful to understand these concepts. I understood most parts of the video. We update parameters of of our distribution by conditioning on other parameters updated from the previous iteration. I still struggle to understand how the example works. Do we always walk in sequence like P(.|B=0), P(.|B=0), P(.|B=1), and P(.|B=1) or is the next iteration dependent on the previous one? If it does how do we determine what we should condition on? I mean there are 4 conditional probabilities corresponding to the example and I can't figure out how you select right one out of 4. I hope my questions are clear. Probability is not one of my strong skills, unfortunately.
Thanks
thanks lamb
really helpful
bro this vedio is allready 19 minutes long . so how can you tell this is a short introduction. 🙂🙂
Great video!! (Congratulations, you got through without your ubiquitous "sort of." Video was thus not distracting.)
Thank you!
Thank you!