
- 12
- 81 558
Afaque Ahmad
Singapore
Registrace 10. 04. 2023
Hey, I’m Afaque Ahmad, a Senior Data Engineer at QuantumBlack, McKinsey & Company and previously at Urban Company (formerly UrbanClap). This channel was created out of my endeavour for teaching and simplifying complex data engineering concepts and, in doing so, perhaps offer a fresh perspective on how we approach them.
Watch out videos on my channel for best-in-class videos on Apache Spark, complex SQL, Advanced Python, and, emerging topics in the area of data engineering.
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
GitHub: github.com/afaqueahmad7117
Contact Email: dataengineer7117@gmail.com
Watch out videos on my channel for best-in-class videos on Apache Spark, complex SQL, Advanced Python, and, emerging topics in the area of data engineering.
LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
GitHub: github.com/afaqueahmad7117
Contact Email: dataengineer7117@gmail.com
Apache Spark Executor Tuning | Executor Cores & Memory
Welcome back to our comprehensive series on Apache Spark Performance Tuning & Optimisation! In this guide, we dive deep into the art of executor tuning in Apache Spark to ensure your data engineering tasks run efficiently.
🔹 What is inside:
Learn how to properly allocate CPU and memory resources to your Spark executors and the number of executors to create to achieve optimal performance. Whether you're new to Apache Spark or an experienced data engineer looking to refine your Spark jobs, this video provides valuable insights into configuring the number of executors, memory, and cores for peak performance. I’ve covered everything from understanding the basic structure of Spark executors within a cluster, to advanced strategies for sizing executors optimally, including detailed examples and calculations.
📘 Resources:
📄 Complete Code on GitHub: github.com/afaqueahmad7117/spark-experiments
🎥 Full Spark Performance Tuning Playlist: czcams.com/play/PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth.html
🔗 LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
Chapters:
0:00 - Introduction to Executor Tuning in Apache Spark
0:37 - Understanding Executors in a Spark Cluster
3:30 - Example: Sizing Executors in a Cluster
4:58 - Example: Sizing a Fat Executor
9:34 - Example: Sizing a Thin Executor
12:50 - Advantages and Disadvantages of Fat Executor
18:25 - Advantages and Disadvantages of Thin Executor
22:12 - Rules for sizing an Optimal Executor
26:30 - Example 1: Sizing an Optimal Executor
38:15 - Example 2: Sizing an Optimal Executor
43:50 - Key Takeaways
#ApacheSparkTutorial #SparkPerformanceTuning #ApacheSparkPython #LearnApacheSpark #SparkInterviewQuestions #ApacheSparkCourse #PerformanceTuningInPySpark #ApacheSparkPerformanceOptimization #ApacheSpark #DataEngineering #SparkTuning #PythonSpark #ExecutorTuning #SparkOptimization #DataProcessing #pyspark #databricks
🔹 What is inside:
Learn how to properly allocate CPU and memory resources to your Spark executors and the number of executors to create to achieve optimal performance. Whether you're new to Apache Spark or an experienced data engineer looking to refine your Spark jobs, this video provides valuable insights into configuring the number of executors, memory, and cores for peak performance. I’ve covered everything from understanding the basic structure of Spark executors within a cluster, to advanced strategies for sizing executors optimally, including detailed examples and calculations.
📘 Resources:
📄 Complete Code on GitHub: github.com/afaqueahmad7117/spark-experiments
🎥 Full Spark Performance Tuning Playlist: czcams.com/play/PLWAuYt0wgRcLCtWzUxNg4BjnYlCZNEVth.html
🔗 LinkedIn: www.linkedin.com/in/afaque-ahmad-5a5847129/
Chapters:
0:00 - Introduction to Executor Tuning in Apache Spark
0:37 - Understanding Executors in a Spark Cluster
3:30 - Example: Sizing Executors in a Cluster
4:58 - Example: Sizing a Fat Executor
9:34 - Example: Sizing a Thin Executor
12:50 - Advantages and Disadvantages of Fat Executor
18:25 - Advantages and Disadvantages of Thin Executor
22:12 - Rules for sizing an Optimal Executor
26:30 - Example 1: Sizing an Optimal Executor
38:15 - Example 2: Sizing an Optimal Executor
43:50 - Key Takeaways
#ApacheSparkTutorial #SparkPerformanceTuning #ApacheSparkPython #LearnApacheSpark #SparkInterviewQuestions #ApacheSparkCourse #PerformanceTuningInPySpark #ApacheSparkPerformanceOptimization #ApacheSpark #DataEngineering #SparkTuning #PythonSpark #ExecutorTuning #SparkOptimization #DataProcessing #pyspark #databricks
zhlédnutí: 5 701
Video
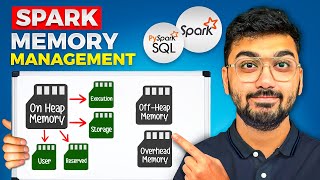

Apache Spark Memory Management
zhlédnutí 6KPřed 3 měsíci
Welcome back to our comprehensive series on Apache Spark Performance Tuning/Optimisation! In this video, we dive deep into the intricacies of Spark's internal memory allocation and how it divides memory resources for optimal performance. 🔹 What you'll learn: 1. On-Heap Memory: Learn about the parts of memory where Spark stores data for computation (shuffling, joins, sorting, aggregation) and ca...

Shuffle Partition Spark Optimization: 10x Faster!
zhlédnutí 5KPřed 6 měsíci
Welcome to our comprehensive guide on understanding and optimising shuffle operations in Apache Spark! In this deep-dive video, we uncover the complexities of shuffle partitions and how shuffling works in Spark, providing you with the knowledge to enhance your big data processing tasks. Whether you're a beginner or an experienced Spark developer, this video is designed to elevate your skills an...

Bucketing - The One Spark Optimization You're Not Doing
zhlédnutí 5KPřed 6 měsíci
Dive deep into the world of Apache Spark performance tuning in this comprehensive guide. We unpack the intricacies of Spark's bucketing feature, exploring its practical applications, benefits, and limitations. We discuss the following real-world scenarios where bucketing is most effective, enhancing your data processing tasks. 🔥 What's Inside: 1. Filter Join Aggregation Operations: A comparison...

Dynamic Partition Pruning: How It Works (And When It Doesn’t)
zhlédnutí 2,6KPřed 7 měsíci
Dive deep into Dynamic Partition Pruning (DPP) in Apache Spark with this comprehensive tutorial. If you've already explored my previous video on partitioning, you're perfectly set up for this one. In this video, I explain the concept of static partition pruning and then transition into the more advanced and efficient technique of dynamic partition pruning. You'll learn through practical example...

The TRUTH About High Performance Data Partitioning
zhlédnutí 4,2KPřed 7 měsíci
Welcome back to our comprehensive series on Apache Spark performance optimization techniques! In today's episode, we dive deep into the world of partitioning in Spark - a crucial concept for anyone looking to master Apache Spark for big data processing. 🔥 What's Inside: 1. Partitioning Basics in Spark: Understand the fundamental principles of partitioning in Apache Spark and why it's essential ...

Speed Up Your Spark Jobs Using Caching
zhlédnutí 3,1KPřed 9 měsíci
Welcome to our easy-to-follow guide on Spark Performance Tuning, honing in on the essentials of Caching in Apache Spark. Ever been curious about Lazy Evaluation in Spark? I’'ve got it broken down for you. Dive into the world of Spark's Lineage Graph and understand its role in performance. The age-old debate, Spark Persist vs. Cache, is also tackled in this video to clear up any confusion. Learn...

How Salting Can Reduce Data Skew By 99%
zhlédnutí 5KPřed 9 měsíci
Spark Performance Tuning Master the art of Spark Performance Tuning and Data Engineering in this comprehensive Apache Spark tutorial! Data skew is a common issue in big data processing, leading to performance bottlenecks by overloading some nodes while underutilizing others. This video dives deep into a practical example of data skew and demonstrates how to optimize Spark performance by using a...

Data Skew Drama? Not Anymore With Broadcast Joins & AQE
zhlédnutí 4,4KPřed 10 měsíci
Spark Performance Tuning Welcome back to another engaging apache spark tutorial! In this apache spark performance optimization hands on tutorial, we dive deep into the techniques to fix data skew, focusing on Adaptive Query Execution (AQE) and broadcast join. AQE, a feature introduced in Spark 3.0, uses runtime statistics to select the most efficient query plan, optimizing shuffle partitions, j...
Why Data Skew Will Ruin Your Spark Performance
zhlédnutí 4KPřed 10 měsíci
Spark Performance Tuning Welcome back to my channel. In this tutorial to dive into this comprehensive Apache Spark tutorial, where we will cover Apache Spark optimization techniques. Are you struggling with Data Skew and uneven partitioning while running Spark jobs? You're not alone! In this video, we dive deep into the world of Spark Performance Tuning and Data Engineering to tackle the common...
Master Reading Spark DAGs
zhlédnutí 12KPřed 10 měsíci
Spark Performance Tuning In this tutorial, we dive deep into the core of Apache Spark performance tuning by exploring the Spark DAGs (Directed Acyclic Graph). We cover the Spark DAGs (Directed Acyclic Graph) for a range of operations from reading files, Spark narrow and wide transformations with examples, aggregation using groupBy count, groupBy count distinct. Understand the differences betwee...
Master Reading Spark Query Plans
zhlédnutí 24KPřed 10 měsíci
Spark Performance Tuning Dive deep into Apache Spark Query Plans to better understand how Apache Spark operates under the hood. We'll cover how Spark creates logical and physical plans, as well as the role of the Catalyst Optimizer in utilizing optimization techniques such as filter (predicate) pushdown and projection pushdown. The video covers intermediate concepts of Apache Spark in-depth, de...
Really waiting to see if you can add some real world use cases to your videos to strengthen our understanding. It will be appreciated a lot man!
Bro do the videos regularly on spark it will be very helpful. Thank you
Great explanation!
Amazing. This is just too good. Will share with my team also.
This is awesome stuff..The executor Tuning concept is explained at a very granular level.
Appreciate it @SandeepPatel-wt7ye, thank you!
sir can you please bring python and sql series for prep of interviews and also basics of it , remaining of the content is just great!
Thank you, appreciate it @chitransh847, Python coming soon :)
I don't think this kind of videos are available on Spark anywhere else. Great work Afaque!
Appreciate it @rgv5966, thank you!
What drawing board are you using for those notes?
Using "Notion" for text, "Nebo" on iPad for the diagrams
@@afaqueahmad7117cool thx!
Hey @afaque, this is top class stuff, thanks for putting in all the effort and making it available for us. Keep going :)
Many thanks @rgv5966, this means a lot, appreciate it :)
This is excellent Spark content videos. It is prefect explanation on Spark performance concept.
Many thanks @dhavaldalasaniya, this means a lot, appreciate it :)
Top Class brother! Simple, Amazing and impactful. You deserve great appreciation to bring these internals. May God bless you with great health, peace, mind and prosperity! Keep growing.
Many thanks @cloudanddatauniverse, this means a lot, thank you for the kind words :)
You are a gem bro. The content that you bring here is terrific. ❤❤❤
Thanks man, @yashwantdhole7645. This means a lot!
you talked about yarn application master. is it driver which contain application master container right? means we are assigning driver memory as 1 gb. right?
if we have already alloting 1 core and 1 gb ram for yarn/os deamons then why do we need to allot seperate 1 core and 1 gb or one executor for yarn resource manager?
Content is useful. Please make more video 😊
Appreciate it @HimanshuGupta-xq2td, thank you :)
Hi Afaque, it is was a really nice video. Never got such detailed understanding anywhere. Do you also provide 1:1 session? If yes, I am highly interested.
Hey @yashwantdhole7645, appreciate the kind words, means a lot. At this moment, I do not take 1:1 sessions, but if you have any questions feel free to shoot an email or comment here in this thread :)
Thanks and please provide contact details .Also do you take classes?
Hey @tushibhaque863, appreciate the kind words. At this moment, I do not take classes, but if you have any questions feel free to shoot an email or comment here in this thread :)
I think its a bit dumb for spark to keep this value static... why not rather have a "target shuffle size(mb/gb)" config in spark. I wish the spark planner was a bit more sophisticated.
You could get a similar effect by turning on AQE and setting "spark.sql.adaptive.advisoryPartitionSizeInBytes" to your desired size. Documentation here: spark.apache.org/docs/latest/sql-performance-tuning.html
@@afaqueahmad7117 Awesome! Thanks for the advice! Your videos have been really helpful!
@Afaque thank you for making these videos. Very helpful. I have questions how do we estimate the data size? We run our batches/jobs on spark and each batches could be processing varying size of data. Some batches could be dealing with 300Gb and some could be 300Mb. How do we calculate optimal number of shuffle partitions?
No clarity is provided on when job is created. The stages are result of shuffle. The task is just a unit of execution
Local distinct on cust id doens't make sense and couldn't understand. How globally it does distinct count if the count is already computed. The reasoning behind why cast doens't push down predicate is not clearly explained and just as it's mentioned in the doc
Great Video!
Appreciate it @jjayeshpawar, thank you!
Lovely!
Will that final actual executor memory again split into user,reserve, unified, overhead memory??
By watching your first 15mins of youtube video and I am awed beyond my words. What a great explanation @afaqueahmad. Kudos to you! Please make more videos of solving real time scenarios using PySpark & Cluster configuration. Again BIG THANKS!
Hey @VenuuMaadhav, thank you for the kind words, means a lot. More coming soon :)
Hi Afaque. Do we have any library or can we create a UDF for understanding why some records got corrupt while reading file? I have a nested XML file with large number of columns and I want to understand why some columns are going into corrupt. Couldn't find anything helpful online. This video would be greatly appreciated.
Hi Afaque, What if the join from Orders is on Product_id and customer_id in products and customers table, will this be still excutor local operation? Also if the Orders table is bucketed on product_id and if the join happens on Customer_id then bucketing the table on product_id alone does not make sense as it will not meet other join columns from orders table as we always not join in product_id in a real world scenario.
Very informative video. I have one question. I’m having databricks cluster and auto scaling is enabled. Will calculations change in that case?
same question to me also. when autoscaling is enabled. how it will tune up the workers and executors inside it.
Just 10 minutes into this notebook and I am awed beyond my words. What a great explanation Afaque. Kudos to you! Please make more videos of solving real time scenarios using Spark UI and one on Cluster configuration too. Again BIG THANKS!
Hi @mohitupadhayay1439, really appreciate the kind words, it means a lot. A lot coming soon :)
hi sir, great content as always. just a question on the last part of the video: if i correctly understood you said to repartition(3) the big table so that rows are evenly repartitioned across the 3 executors and then apply the broadcast join. But in the code part you only performed a broadcast join without repartition(3). Why that? I am a little bit confused about that part. thanks a lot
Hey @retenim28, thank you, appreciate it. On the question - you're correct that I mentioned doing a `repartition(3)` when the table is big so that the rows get evenly partitioned. Reason why I don't do a `repartition(3)` in the code is because sample transactions table I'm using (supposedly the bigger table) isn't very big - hence a repartitioning to even out data is not needed. Hope that clarifies :)
@@afaqueahmad7117 this clatifies a lot, thank you. Another question: `repartition(3)` function involves a shuffle, so theoretically it would be better avoiding that and only use broadcast join, as you did in the video. So, it seems to me there are two possible situation: 1. make `repartition(3)` and then broadcast join: this involves a shuffle (bad) of big table, but finally skew data problem is solved so each core will process the same amount of data; 2. avoid `repartition(3)` and then broadcst join: there is no shuffle (good) of big table, but a specific core is forces to work with a huge amount of data compared to the remaining two. Which is the best path? In your code I tried both options and it looks like it's better avoiding `repartition(3)`. Am I missing something on this point? Sorry about the long answer.
Thanks Afaque. Terminology wise, Is this the same as Filter pushdown which you explained during the Query Plan video?
Hey @anandchandrashekhar2933 Appreciate it :) On the question - DPP is different from "filter pushdown", although it uses filter pushdown to prune the large dataset based on the filters from the smaller dataset. It's effective when you have a large and a small dataset (which can be broadcasted) and want to use the small dataset to filter records from the large dataset at scan-time
Hi Afaque, thank you again for this gold content. I believe that a similar series on Delta Lake optimizations would greatly benefit everyone. I realized that when i couldnt do bucketing with delta tables while following your guide.I hope you have plans to make one :)
On Delta tables you would relay on optimization functions, so Z Ordering. It's achieving the same things as bucketing but by using sorting on the data so the same data resides on the same files. BUT Zordering has some advantages over bucketing as with ZOrdering you wont create a small file problem even on high cardinality columns as the ZOrder/Optimization function will compact your files into 1GB parquet files.
Thank you so much again! I have one follow up question about partition during writes. If I use a df.write but specify no partitioning column or use repartition, could you pls let me know how many partitions does spark write to by default? Does it simply take the number of input partitions (total input size / 128m) or assuming if shuffling was involved and the default shuffle partitions being used were 200 , does it use that shuffled partition number ? Thank you
Hey @anandchandrashekhar2933, so basically it should fall into 2 categories: 1. If shuffling is performed: Spark will use the value of `spark.sql.shuffle.partitions` (defaults to 200) for the number of partitions during the write operation. 2. If shuffling is not performed: Spark will use the current number of partitions in the DataFrame, which could be based on the input data's size or previous operations. Hope this clarifies :)
Precious 30 minutes, quality content
Thank you @sasadsasadsad, appreciate it :)
Wow! Thank you Afaque, this is incredible content and very helpful!
Appreciate it @anandchandrashekhar2933, thank you!
Absolute gem ❤❤ would like to have video on handling real time scenarios (handle slow running job, oom etc)..
Great work, going good. I hope you cover 2 more topic of driver oom and executor oom. Why it happens and how we can tackle it.
Really great content, all of your videos. Thannk you!! Just had a question out of curiousity - Does AQE only coalesce shuffle partitions or depending on the need, increase the shuffle partitions beyond 200?
Hey @anandchandrashekhar2933, appreciate the kind words. Yes, AQE can do both - increase (split) and decrease (coalesce) the number of shuffle partitions. A clear example is this one is in the Spark DAGs video where 1 skewed partition was split into 12 because that 1 partition was skewed. Refer here: czcams.com/video/O_45zAz1OGk/video.html
@@afaqueahmad7117 Ah thank you for that. That really made it very clear. For some reason, i couldnt replicate the same when i ran your notebook on Databricks, even though i disabled broadcast hash join, it still ended up using broadcast instead of the AQE coalesce followed by sort merge. Maybe seems like something specific about the spark version i am currently on. But thats all right. Thank you again :)
@@afaqueahmad7117 Thank you! That makes sense. For some reason, I couldnt replicate it when running your notebook on Databricks, even if i disable broadcash hash join, it still ended up using it, instead of how you showed it, that is a AQE coalesce followed by a sort merge join. Maybe something specific with the spark version that i was on. But that's all right. Thank you again!!
what if the values are unique in join 1 to 1 join? will it create skew
I really enjoy your videos. Thanks for sharing your knowledge. I have a question about how you create these videos. It is an amazing way to create tutorial videos. Do you mind share what tools you use to make these videos? Thanks
Thank you @Wonderscope1, really appreciate it. I use Notion and Miro :)
@@afaqueahmad7117 I am familiar with Notion as project managmeent tool I didn't know it can help with video production. I need to look into that. Thanks 😊
Sorry I meant Notion for the code snippets. I use Ecamm Live for video production :)
@@afaqueahmad7117 perfect that's what I was looking for . Thanks :)
Please make a dedicated video on shuffle partition... how it behaves when it's increased or decrease from 200
Hey @SHUBHAM_707, have you watched this - czcams.com/video/q1LtBU_ca20/video.html
At 16.39 , when u use repartition(3) , why there are 6 files?
Hey @Amarjeet-fb3lk, Good question, I should have pulled the editor sidebar to the right for clarity. It's 3 files actually, the remaining 3 files are `.crc` files which is created for data integrity by Spark - to make sure the written file is not corrupted.
Excellent.. pls keep posting on internals of spark
Thanks @prabas5646, appreciate it :)
Great explanation man! Thank you! What's the editor that you use in the video to read query plans?
Thanks @venkateshkannan7398, appreciate it. Using Notion :)
Thanks Afaque for this great tutorial. This will really help while working on Spark Optimization. It would be of great help if you can tell how do you deal with this type of questions: - spark cluster size -- 200 cores and 100 gb RAM data to be processed --100 gb give the calculation of spark for driver memory, driver cores, executor memory, overhead memory, number of executors
Hey @yatinchadha1803, thanks for the kind words, really appreciate it. Regarding the question - after watching the video, it should be a cakewalk :)
@@afaqueahmad7117 can you please guide on how to calculate the driver memory and driver cores?
Excellent job 🙌
Thanks @prasadrajupericharla5545, appreciate it :)
Very nice explanation! Thank you for making this video.
Thanks @purnimasharma9734, appreciate it :)
Hell Afaque, your tutorials are excellent and I learnt so much about optimization techniques. I am wondering if you can add some real world use cases to your videos to strengthen our understanding. It will be appreciated a lot.
I have two accounts in CZcams and subscribed in both, Reason is you are putting some serious effort into the content. Beautiful Diagrams clear explanation accurate information is beauty of your content. Thanks, Afaque Bhai
Bohot shukriya @coledenesik bhai :) This comment made my day. Thank you for appreciating my efforts, it means a lot to me brother <3
After 3.0 salting is not useful
Hey @gudiatoka, I wish it was so, but just in case you're referring to AQE as the solution, it isn't always very helpful, so you still need to resort to salting.
@@afaqueahmad7117 yes AQE and partition is useful and in case of larger dataframe when salting key applied to lower df it duplicated records making it more skewed then the concept of salting not valid at least for me...may be it servers different